Use Temporal as a control plane, not as a data plane - @maxim
Problem Link to heading
In a typical ETL-like scenario, the data come as streams of rows. The workflow need to wait for a row to arrive and then kick off a series of processing steps synchronously or asynchronously. Example like:
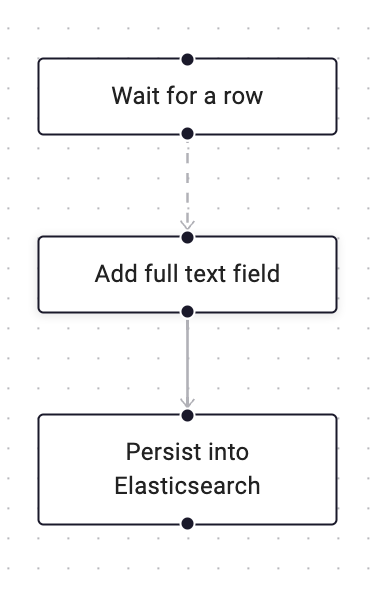
From intuition, we might implement the workflow like this:
...
sig := workflow.GetSignalChannel(ctx, "receiveRow")
// signal internally or externally to "receiveRow" channel
for ctx.Err() == nil { // break if context cancelled
var row any
more := sig.Receive(ctx, &row)
workflow.Go(ctx, func(ctx workflow.Context) {
err := workflow.ExecuteActivity(ctx, AddFullTextToRow).Get(&row)
if err != nil { ... }
err = workflow.ExecuteActivity(ctx, PersistElasticsearch).Get(nil)
if err != nil { ... }
})
if !more {
break
}
}
...
However, one would quickly realise this would not work because all signals are recorded in the workflow’s history and the history would quickly run into the maximum limit: Temporal Docs: Event History
The problem here hits home with what @maxim stated: Temporal should be the control plane, not data plane. And yet we are piping all the rows through temporal. This obviously goes against what Temporal is designed for.
So clearly, we need a data plane, but how would a data plane fit in this picture?
Our Approach Link to heading
TL;DR; combine Continue As New with an external queue.
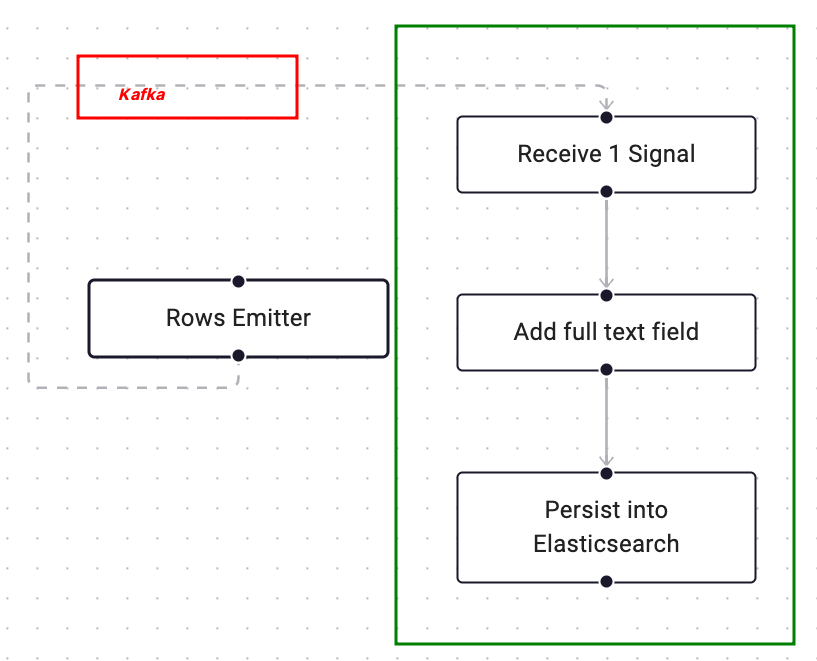
In the above flow, we introduce a “data plane” using Kafka, and have a child workflow that have first activity subscribe to a Kafka topic, receive one row and return the result. Code would look like this:
parentWorkflow.go:
topicName := createTopic()
// here we launch child workflow first so that we don't miss any message
childFuture := workflow.ExecuteChildWorkflow(ctx, etlPipeline, topicName)
// Emit the rows in an activity, e.g. iterate through a database table:
err := workflow.ExecuteActivity(ctx, rowsEmitter, topicName).Get(ctx, nil)
...
In the above snippet, we created the topic and pass the topic name to start of the ChildWorkflow . Then we start the rowsEmitter activity that streams the rows to the Kafka topic.
childWorkflow.go:
var row any
err = workflow.ExecuteActivity(ctx, ReceiveRow, topicName).Get(&row)
err = workflow.ExecuteActivity(ctx, AddFullTextToRow, row).Get(&row)
err = workflow.ExecuteActivity(ctx, PersistElasticsearch, row).Get(&row)
...
return workflow.NewContinueAsNewError(ctx, etlPipeline)
In ChildWorkflow, we always run ReceiveRow as the first activity which subscribes to the topic and returns the row content for the next steps to carry on.
After all activity finishes, just return ContinueAsNew to process another row.
We won’t run into history limit because each execution counts as a new workflow.
In this mode, we synchronously process each row but we can easily add a worker pool in the parent workflow to launch several child workflow. However, the queue configuration needs to be done carefully because we want consumers to retrieve different rows from the queue not the same row to be processed twice.
Caveats Link to heading
- workflow replay would require custom gluing In this design, although we have an external queue deals with data streaming, history replay is possible by querying child workflow with parent workflow id and all the data rows would be in the history of each child workflow
- garbage collection As child workflow history can get huge, you would need a good garbage collection strategy (i.e. utilising a DELETE_HISTORY_EVENT timer task: https://community.temporal.io/t/domain-history-cleanup/206
- performance We haven’t run any benchmark or any comparison with other “big data” processing. In our scenario, we need the reliable execution. However, we would like to do certain perfs to know what’s the limit.